For two decades we have run a network of content properties, watching server logs the whole way.
The most disruptive shift we have seen in that time is not a Google update. It is the arrival of a new class of visitor: AI crawlers that do not browse the way people or search engines do, and that increasingly decide whether your brand gets quoted inside ChatGPT, Claude, Gemini, and Perplexity answers.
Most brands are still optimizing for a reader who is no longer the one making the decision.
AI Crawler Optimization is the practice of making your site technically accessible, semantically clear, and trustworthy to those bots, so that large language models can crawl it, understand it, and confidently cite it.
It sits one layer above classic technical SEO and answer engine optimization. SEO got you ranked.
AEO got you structured for answers. AI crawler optimization is about being a successful visit for the machine that does the citing in the first place. If the crawler cannot read you cleanly, nothing downstream matters.
This is a practitioner guide, not a prediction piece. Everything below reflects what AI crawlers actually do in 2026, including a few places where the popular advice has already gone stale.
The AI crawler economy, in numbers
AI bots are no longer a rounding error in your traffic. In a single recent month across one major hosting network, the volume looked like this:
| 569M | Monthly requests from OpenAI’s GPTBot across Vercel’s network, with Anthropic’s ClaudeBot close behind at roughly 370M. Combined, that is about 20% of Googlebot’s volume in the same window. |
| 0 | Major AI crawlers that fully render JavaScript. Independent testing by Vercel and Merj found none of them execute client-side JS. They read your initial HTML and stop. |
| 1-5s | Typical fetch timeout for AI crawlers. Slow or bloated pages get partially read or skipped entirely. |
| ~10% | Share of sites that have published an llms.txt file. Crawler interest in it remains negligible, which we will get to honestly below. |
The takeaway is simple. A growing share of the entities forming an opinion about your brand are bots that judge you on raw HTML, in a couple of seconds, with no patience for the front-end stack your team is proud of.
What we see across 65 million AI-crawler requests
Most write-ups on AI crawlers borrow a headline number from one hosting provider. We pulled our own. Across a portfolio of 38 sites we logged 65.1 million verified AI-bot requests between October 2025 and July 2026, and a few things stand out that change how you should prepare.
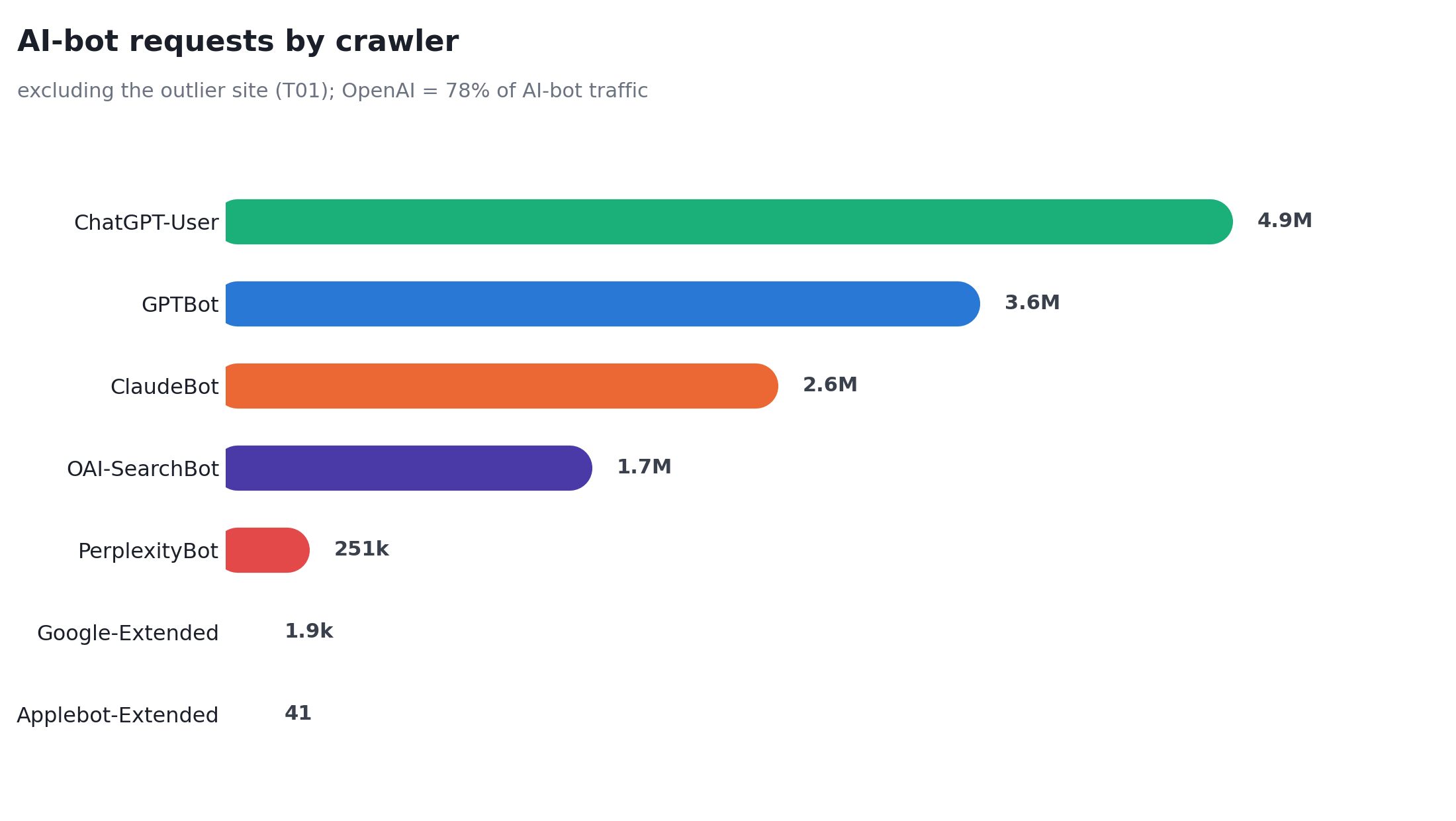
One company is almost the whole story. OpenAI’s three bots (GPTBot, ChatGPT-User, OAI-SearchBot) are 94% of all AI-bot traffic, and still 78% once we remove our single highest-volume outlier site. Anthropic’s ClaudeBot is a distant second, Perplexity is a rounding error, and Google-Extended is effectively absent (more on that below). If you optimize for one operator, optimize for OpenAI, and make sure you never accidentally block it.
Crawling is not the same as being read, and the read is what you want. GPTBot crawls to train. ChatGPT-User fetches a page live because a real person’s answer needed it. That second bot is your visibility signal, and it is the cleanest traffic on the site.
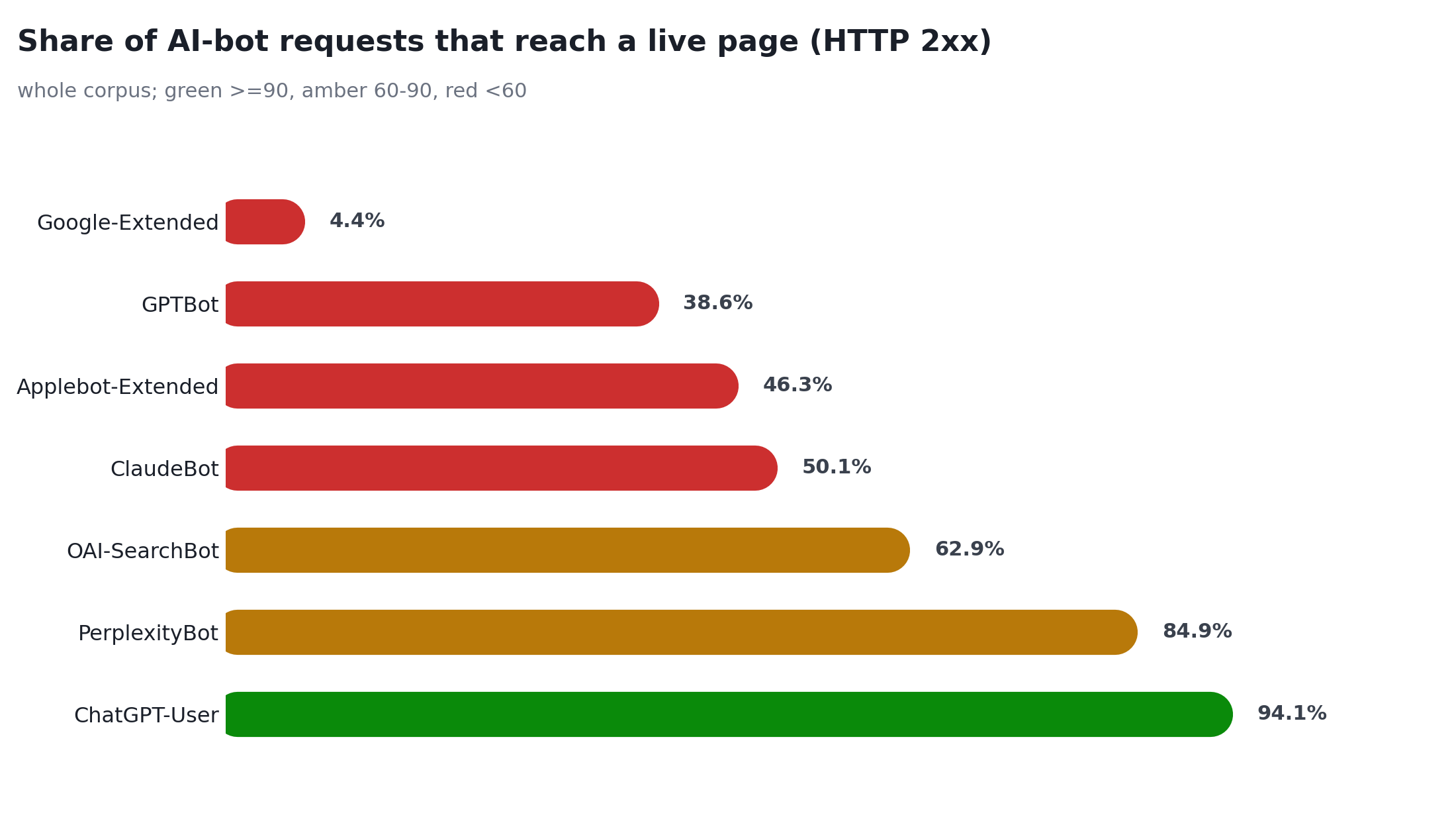
A lot of crawler budget is quietly wasted, and it is fixable. ChatGPT-User reaches a live page 94% of the time. GPTBot manages only 39%, and ClaudeBot 50%. On one of our larger sites, ClaudeBot lost 46% of its requests to server (5xx) errors for months, a firewall or origin quietly failing an AI crawler at scale. Almost nobody checks this. Pull your own server or CDN logs, group by bot, and look at the status codes. It is one of the highest-return AI-crawler fixes available and it never shows up in a normal audit.
Nobody is actually blocking. Across all 38 sites and 65.1 million requests, we recorded zero blocked and zero challenged AI-bot requests. The “block the bad bots” debate is louder than the practice.
Do this: track ChatGPT-User hits as your “AI reads you” metric, audit per-bot status codes for the silent 5xx and redirect leak, and confirm OpenAI’s bots are never rate-limited or firewalled by accident.
Method note: verified-bot classification via Cloudflare across a 38-site portfolio, Oct 2025 to Jul 2026. Full data is open at the dataset page.
How AI crawlers see your brand (and how that differs from Googlebot)
To optimize for these bots you have to drop the assumption that they behave like search crawlers. They do not. There are two broad jobs they perform, and the difference matters for strategy.
Training crawlers vs retrieval crawlers
| Crawler type | What it does | Example user agents | Why it matters |
|---|---|---|---|
| Training crawlers | Harvest large content corpora to train and update models, asynchronously and offline. | GPTBot, ClaudeBot, PerplexityBot, CCBot | Shapes what the model “knows” about you by default, before any live search runs. |
| Retrieval crawlers | Fetch fresh pages at or near query time to ground a live answer or agent action. | OAI-SearchBot, ChatGPT-User, PerplexityBot (live mode) | This is the visit that most directly feeds a citation. A hit here is your strongest visibility signal. |
| Opt-out tokens | Not crawlers at all. Directives that tell an existing crawler whether it may use your content for AI training. | Google-Extended, Applebot-Extended | Widely misreported as bots. They make no requests and never appear in your logs. |
That last row trips up a lot of agencies. Google-Extended and Applebot-Extended are switches, not visitors.
Blocking Google-Extended opts you out of Gemini training while leaving Googlebot, and therefore AI Overviews, untouched. Knowing the difference is the line between a deliberate policy and an accidental self-block.
The rendering gap is the whole game
Googlebot spent a decade building a rendering engine that executes your JavaScript before indexing. AI crawlers did not. They fetch your HTML and, in most tested cases, never run a line of script. They will even download your JS files (Claude’s crawler does this on roughly a quarter of fetches, ChatGPT’s on about one in nine) and then treat them as inert text rather than executing them.
What this means in practice
If your product descriptions, comparison tables, pricing, or FAQ answers only appear after JavaScript runs, an AI crawler sees an empty shell where your most citable content should be. There is no partial credit. The content is either in the initial HTML or it is invisible to the model.
The fastest diagnostic you can run today: load a key page, disable JavaScript, and reload. Whatever disappears is roughly what GPTBot, ClaudeBot, and PerplexityBot see. If your value proposition vanishes, you have a rendering problem, not a content problem.
Robots.txt and llms.txt: your AI access policy, told straight
Two files govern how openly you greet AI crawlers. One of them works. The other is more nuanced than most 2026 advice admits.
Robots.txt is the real lever
Robots.txt is the standard that reputable AI crawlers actually respect, and the most common mistake we find in audits is accidental blocking.
A broad Disallow rule, or a generic bot block inherited from an old configuration, can quietly remove you from the training and retrieval pipelines that feed AI answers. The fix is to be explicit:
- Allow the crawlers that drive citations on your public content: GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot.
- Disallow sensitive areas regardless of bot: accounts, checkout, internal search results, staging, and thin near-duplicate archives.
- Decide deliberately on training-only crawlers like CCBot, and on opt-out tokens like Google-Extended, based on whether you want your content used for model training versus only for live retrieval.
- Add crawl-delay only if your logs show real strain. Throttling a citation engine to save bandwidth is usually a bad trade.
llms.txt: useful to ship, but not the citation lever it is sold as
You will read a lot of advice telling you to build and maintain an llms.txt file as your “AI orientation” document. Here is the honest 2026 picture, because getting this wrong makes a brand look behind the curve.
As of this year, no major LLM provider, including OpenAI, Anthropic, Google, Meta, or Mistral, has committed to reading llms.txt as a signal in its production answer surfaces. Google has said so on the record.
Adoption sits at roughly one in ten sites, and direct crawler requests for the file are statistically negligible. Publishing it will not, on its own, change how often you get cited.
That does not make it worthless. It is cheap to ship, and the real value is forward-looking and agent-facing: IDE assistants, MCP servers, and in-product AI tools increasingly fetch it as a machine-readable map of your documentation and authoritative sections.
If your category has any agentic angle, comparison shopping, vendor research, booking, or developer tooling, a clean llms.txt is sensible infrastructure. Just file it under “low-cost, future-facing,” not under “this is how we get cited.”
The Mostash position
Spend your robots.txt time on access hygiene, because that is enforced. Treat llms.txt as half a day of insurance for the agentic web, not as a visibility tactic. Citations are won in your HTML and your entity graph, not in a metadata file the answer engines do not yet read.
Technical foundations: making the crawler a successful visit
Once a crawler can reach you, the job is to make the visit fast, complete, and clean. These are the patterns that correlate with AI crawlers reading you fully rather than bailing.
Render server-side or statically for anything you want cited
Move your critical content templates to server-side rendering (SSR) or static generation so the meaningful text, headings, tables, schema, and internal links live in the initial HTML response.
Progressive enhancement with JavaScript for interactivity is fine. What is not fine is depending on the client to assemble the content that defines your value.
Win the speed budget
Because AI crawlers work inside a 1 to 5 second timeout, performance is a visibility issue, not just a user experience one.
Prioritize a fast first response, aim for time to first byte under roughly 200 milliseconds on important pages, compress your HTML, inline critical CSS, and keep media weight down.
To a bot on a tight clock, every extra half-second is an invitation to read less of you or move on to a faster competitor.
Eliminate crawl waste
AI crawlers tend to hit more dead ends than traditional bots, often because of outdated assets and messy URL patterns. Every 404 or redirect chain they waste a fetch on is content they did not read.
- Keep XML sitemaps accurate, segmented, and current.
- Use consistent URL patterns and avoid infinite faceted or parameter URLs.
- Repair high-volume 404s and collapse redirect chains.
- Monitor 4xx and 5xx rates specifically for AI user agents in your logs.
Content and schema: teaching AI what you are the best at
Clean access gets you read. Structure and substance get you selected. Across our own properties, the content that earns AI citations shares a recognizable shape.
Structure for extraction, not just consumption
LLMs lift answers out of pages. Make that easy. Open each section with a direct, self-contained answer, then elaborate underneath. Use descriptive H2 and H3 headings that mirror the questions real people ask.
Lean on tables for comparisons and ordered lists for processes, because those map cleanly onto how a model assembles a response. A page that buries its answer three paragraphs deep is a page the model has to work to quote, so it often quotes someone else.
Build genuine topical depth
Thin, isolated pages rarely get cited. Clustered, interlinked coverage around a pillar topic does. The pattern we see repeatedly is that depth and internal linking that reflects real entity relationships, not a single SEO post, is what signals to a model that you are an authority worth grounding to.
Make your entities legible with schema
AI systems build a working knowledge graph from your content, and structured data is a shortcut into it. The schema types that earn their keep in 2026:
| Schema type | What it clarifies for the model |
|---|---|
| Organization | Who you are as an entity, your areas of expertise, and how your brand connects to people and products. |
| Article / BlogPosting | Authorship, publish and update dates, and topical focus. |
| FAQPage | Discrete question and answer pairs that slot directly into AI responses. |
| HowTo | Step sequences that models can reproduce as instructions. |
| Product / Review | Attributes, pricing context, and credibility signals for commercial queries. |
One rule overrides all of them: your schema must match your visible content. Markup that describes something the crawler cannot see in the HTML is a trust liability, not an asset.
Freshness counts
Add clear publication and last-updated dates. Retrieval crawlers favor content they can confirm is current, and a visible, accurate update date is one of the cheapest grounding signals you can give them.
Brand trust: why citations are a network effect
AI systems increasingly evaluate experience, expertise, authoritativeness, and trustworthiness before they decide to quote you, and they do it across more than your own domain.
On-page trust signals
- Author bylines with real credentials and substantive bios. If you do not have a named, qualified author, attribute to your editorial team rather than inventing one.
- Transparent About pages, editorial standards, and reachable contact information, which matter even more on topics that affect money or wellbeing.
- Outbound citations to reputable sources and internal references to your own original research.
Off-site consistency
Models cross-check. The brands that get cited confidently tend to have their identity lined up everywhere a crawler might verify it: on-site information, business profiles, and reputable directories and review platforms all telling the same story. Conflicting facts across those surfaces introduce doubt, and doubt suppresses citations.
AI visibility angle
For an answer engine, trust is a network effect. The more consistently your name, your expertise, your reviews, and your entity relationships align across the web, the more confidently a model can ground a sentence to you instead of hedging or citing a competitor. Citations beat mentions, and consistency is what turns one into the other.
Measuring AI visibility: from server logs to answer share
You cannot manage what you do not watch, and most analytics stacks were not built to see AI crawlers. Two layers of measurement matter.
Crawl-side: are the bots reading you well?
- Visit frequency and patterns for each AI user agent (GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot, and the live ChatGPT-User fetcher).
- Crawl depth: which sections and how many levels in the bots actually reach.
- Error and status code rates by user agent. A spike in 404s or empty 200s for AI bots is a visibility leak.
- Response time for AI bot requests compared with human traffic.
Answer-side: are you getting cited?
The crawl is the input. The citation is the outcome. Periodically test your brand and priority topics in ChatGPT, Gemini, Claude, and Perplexity, and track where and how you appear: cited with a link, mentioned without one, or absent while a competitor takes the slot.
This is your answer share, and it is the metric that connects all the technical work above to revenue.
The tooling falls into three tiers: traditional SEO platforms that have bolted on AI bot segments and AI search visibility, specialized AI visibility platforms that track how models understand and cite you, and custom log dashboards that segment by AI user agent.
Most brands start with logs they already have, because the access and error picture lives there and costs nothing new.
The 90-day AI crawler optimization plan
You do not have to do all of this at once. This is the phased sequence we use to take a brand from invisible to citable.
Days 1-30 :: Access and infrastructure
Make sure the bots can read you at all
- Audit robots.txt and remove any accidental AI crawler blocks.
- Run the JavaScript-disabled test on your most important templates and prioritize SSR or static rendering for anything that disappears.
- Fix high-volume 404s, collapse redirect chains, and refresh sitemaps.
- Improve TTFB and HTML payload on priority pages to stay inside the crawler timeout.
- Stand up log monitoring segmented by AI user agent to set a baseline.
Days 31-60 :: Content and structure
Make yourself worth quoting
- Rewrite priority pages to answer the core question early, then go deep.
- Build or strengthen topical clusters with internal links that reflect real entity relationships.
- Implement Organization, Article, FAQPage, and HowTo schema that matches visible content.
- Add and surface accurate publish and last-updated dates.
- Publish at least one piece of original research or first-party data others can cite.
Days 61-90 :: Trust and measurement
Become the source, then prove it
- Align on-site facts with business profiles, directories, and review platforms.
- Strengthen author bylines, About pages, and editorial transparency.
- Run a baseline answer-share test across ChatGPT, Gemini, Claude, and Perplexity.
- Set a monthly cadence to retest citations and review AI crawler logs, because the systems change weekly and a strategy from three months ago is already aging.
- Decide on llms.txt deliberately as agentic-web insurance, not as a citation tactic.
Where this fits
AI crawler optimization is the foundation layer of answer engine optimization. Get a crawler to read you fully, understand your entities clearly, and trust your brand consistently, and you have done the hard part of becoming the source AI systems cite.
Everything else is iteration, and iteration never stops, because the answer engines do not either.
Frequently asked questions
Is AI crawler optimization different from SEO?
Yes, though it builds on the same foundations. Classic SEO optimizes for a search engine that ranks pages, and Googlebot can render your JavaScript before doing so. AI crawler optimization targets bots that mostly read raw HTML in a few seconds and feed large language models, which then decide whether to cite you. The technical hygiene overlaps, but the bar for rendering, speed, and entity clarity is higher and less forgiving.
Do AI crawlers read JavaScript?
Mostly no. Independent testing has found that the major AI crawlers, including GPTBot, ClaudeBot, and PerplexityBot, do not execute client-side JavaScript. Some download your JS files but treat them as inert text. If your content only appears after scripts run, those bots see an empty shell. Server-side rendering or static generation solves this. Googlebot, which powers Google’s AI Overviews, is the exception that does render JavaScript, with delays.
Should I create an llms.txt file?
It is optional and currently low-impact for citations. As of 2026, no major AI provider has committed to reading llms.txt in its answer surfaces, adoption is around one in ten sites, and crawler interest is negligible. It is cheap to publish and has a forward-looking role for agentic tools that fetch it as a documentation map, so treat it as low-cost insurance rather than a visibility lever. Your robots.txt, rendering, and entity work matter far more.
Which AI crawlers should I allow in robots.txt?
For most public-facing brands, allow the crawlers that drive citations: GPTBot, ClaudeBot, PerplexityBot, and OAI-SearchBot. Keep sensitive areas like accounts, checkout, and staging disallowed for all bots. Decide separately on training-only crawlers and on opt-out tokens such as Google-Extended, which control AI training use without affecting Google search or AI Overviews.
How do I know if AI systems are citing my brand?
Measure both ends. On the crawl side, segment your server logs by AI user agent to see who is reading you, how deeply, and with what error rates. On the answer side, periodically query ChatGPT, Gemini, Claude, and Perplexity for your brand and key topics, and record whether you are cited with a link, mentioned without one, or missing entirely. That answer share is the metric that ties the technical work to actual visibility.
How long does it take to see results?
Access and rendering fixes can change what crawlers see within days of recrawling. Content, schema, and trust signals compound over weeks as models retrain and retrieval surfaces update. A focused 90-day program is enough to move a brand from accidentally invisible to reliably readable and citable, but maintenance is ongoing because the answer engines evolve constantly.


